Introducing Meka: An Open-Source Framework for Building Autonomous Computer Agents
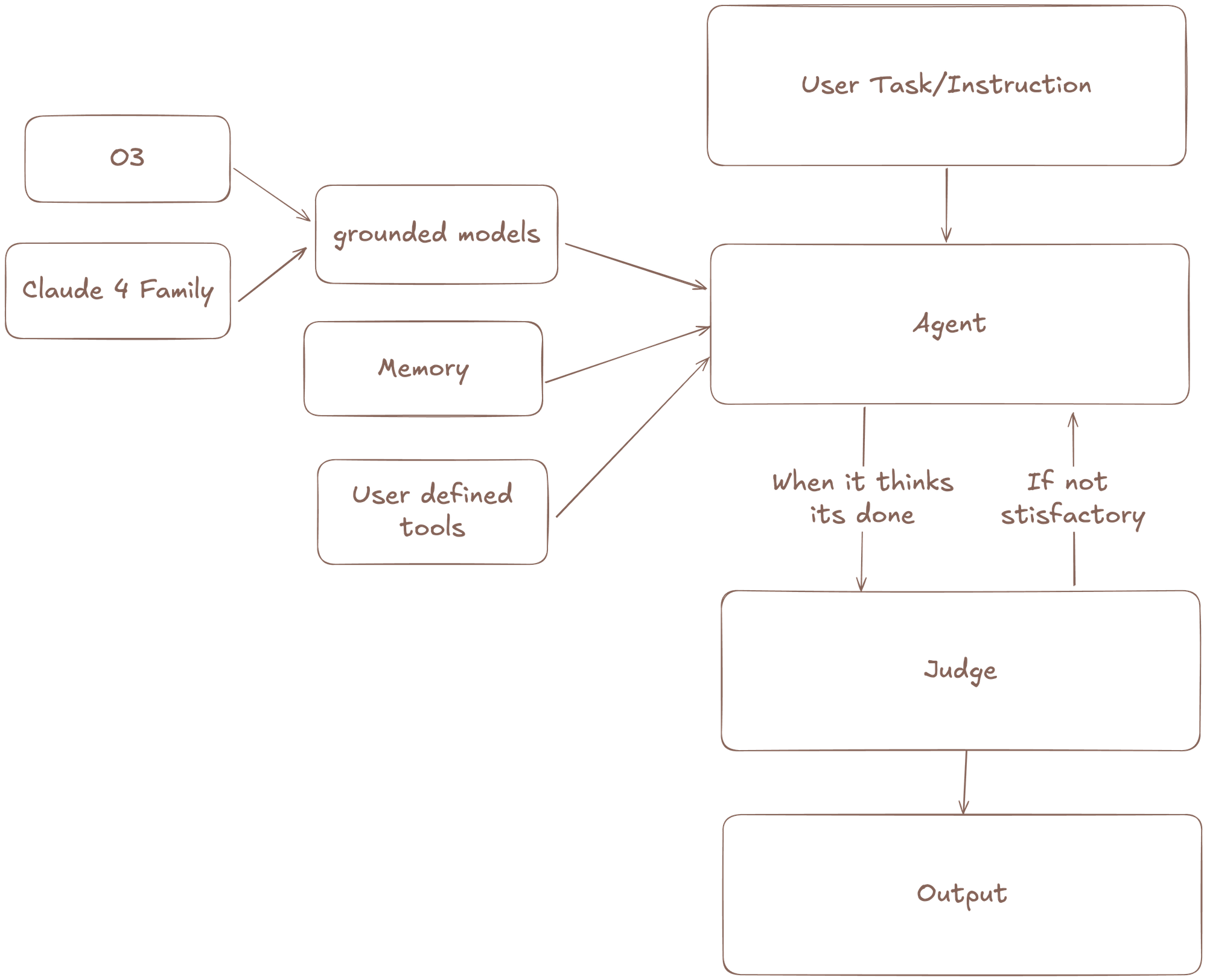
Architecture behind Meka's state of the art webArena performance.

In today's digital world, many tasks are repetitive. What if you could automate them?
With the advancements in Multi-Modal LLMs, we're excited to introduce Meka. Meka achieves state-of-the-art (SOTA) performance on WebArena and is an open-source framework for building computer use agents.
We designed Meka to be powerful and flexible. It's built on a few key principles that we believe are crucial for creating effective autonomous agents. In this post, we'll walk you through Meka's architecture, its impressive performance on the WebArena benchmark, and our vision for its future.
Meka's Architecture
Meka’s design is modular and powerful. LLM's acts as the agent's brain, directing a set of tools to interact with a web browser.
Vision-First Approach
Meka takes a vision-first approach. We rely on screenshots to understand and interact with web pages. We believe this allows Meka to handle complex websites and dynamic content more effectively than agents that rely on parsing the DOM.
To that end, we use an infrastructure provider that exposes OS-level controls, not just a browser layer with Playwright screenshots. This is important for performance as a number of common web elements are rendered at the system level, invisible to the browser page. One example is native select menus. Such shortcoming severely handicaps the vision-first approach should we merely use a browser infra provider via the Chrome DevTools Protocol.
By seeing the page as a user does, Meka can navigate and interact with a wide variety of applications. This includes web interfaces, canvas, and even non web native applications (flutter/mobile apps).
Mixture of Models
Meka uses a mixture of models. This was inspired by the Mixture-of-Agents (MoA) methodology, which shows that LLM agents can improve their performance by collaborating. Instead of relying on a single model, we use two Ground Models that take turns generating responses. The output from one model serves as part of the input for the next, creating an iterative refinement process. The first model might propose an action, and the second model can then look at the action along with the output and build on it.
This turn-based collaboration allows the models to build on each other's strengths and correct potential weaknesses and blind spot. We believe that this creates a dynamic, self-improving loop that leads to more robust and effective task execution.
Contextual Experience Replay and Memory
For an agent to be effective, it must learn from its actions. Meka uses a form of in-context learning that combines short-term and long-term memory.
Short-Term Memory: The agent has a 7-step lookback period. This short look back window is intentional. It builds of recent research from the team at Chroma looking at context rot. By keeping the context to a minimal, we ensure that models perform as optimally as possible.
To combat potential memory loss, we have the agent to output its current plan and its intended next step before interacting with the computer. This process, which we call Contextual Experience Replay (inspired by this paper), gives the agent a robust short-term memory. allowing it to see its recent actions, rationales, and outcomes. This allows the agent to adjust its strategy on the fly.
Long-Term Memory: For the entire duration of a task, the agent has access to a key-value store. It can use CRUD (Create, Read, Update, Delete) operations to manage this data. This gives the agent a persistent memory that is independent of the number of steps taken, allowing it to recall information and context over longer, more complex tasks.
Self-Correction with Reflexion
Agents need to learn from mistakes. Meka uses a mechanism for self-correction inspired by Reflexion and related research on agent evaluation. When the agent thinks it's done, an evaluator model assesses its progress. If the agent fails, the evaluator's feedback is added to the agent's context. The agent is then directed to address the feedback before trying to complete the task again.
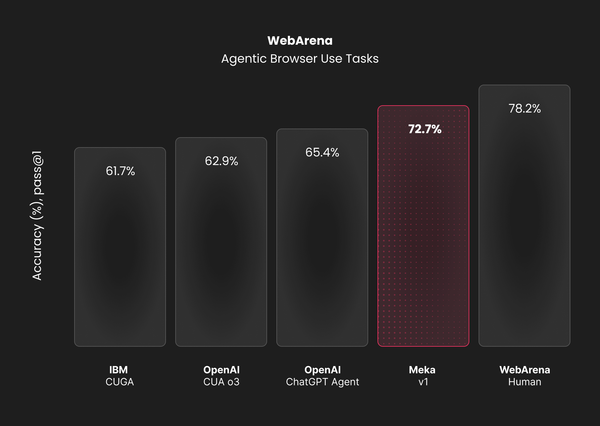
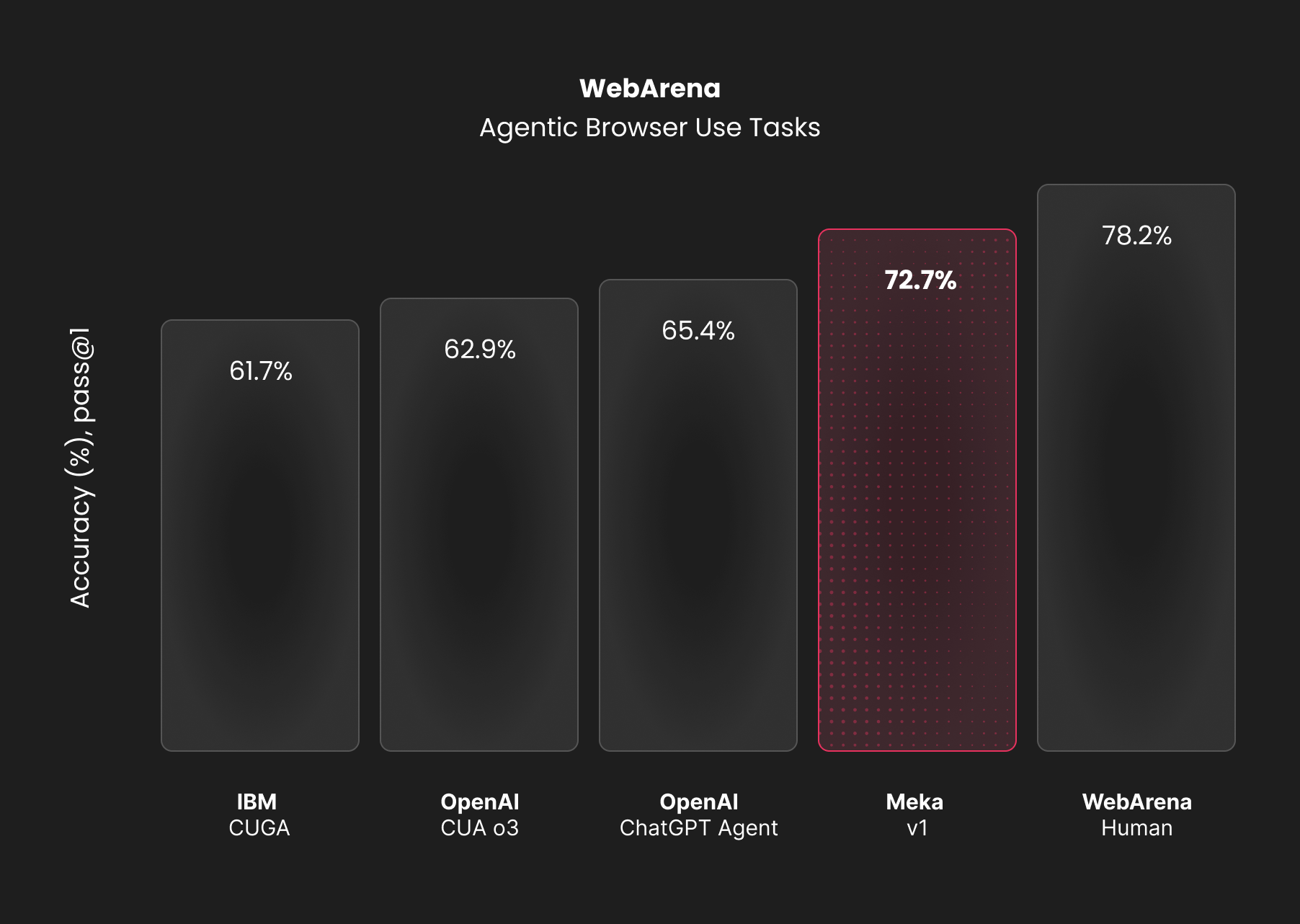
SOTA on WebArena
We validated our approach on the WebArena benchmark. We're proud to announce that Meka achieves SOTA performance (72), beating out the current SOTA (65.8%). This result validates our multi-model strategy and the architectural choices we've made.
For more details on how the benchmark was done, checkout our evaluation article.
Why Open Source?
The field of autonomous agents is growing rapidly, but we all have more work to do. We hope that in open-sourcing, we'd invite collaboration and innovation that will let us continue to push the frontier.
The Road Ahead
We're just getting started. Here are some of the areas we're excited to explore next:
- More Tools: We will continue to expand Meka's toolset based on community use cases. For example, data extraction could be done via the clipboard instead of visually through the screenshot. Giving shell access for running code seems like a natural next step. Supporting MCP would also unlock interoperability with many other tools.
- Smarter Prompts: Our current system prompt is simple. We plan to explore more advanced prompting techniques to improve performance.
- Open-Source Models: Our framework is open, but the models we use are not. We want to test how Meka performs with open-source models.
- Better Memory: We plan to build more advanced memory systems to help the agent remember information across multiple sessions on the same site.
Conclusion
We introduced Meka, a state-of-the-art open-source framework for building autonomous web agents. Its modular architecture leverages a mixture of models, in-context learning, and a composable tool system.
Get started today by starring our GitHub repository.
Try running your own task now on our hosted cloud with $10 of free credits for a limited time.
We look forward to seeing what you do with Meka!