Meka Achieves State-of-the-Art Performance for Computer Use

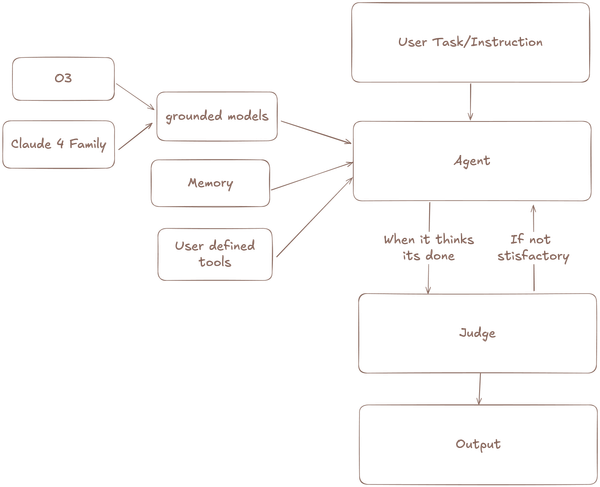
Introduction
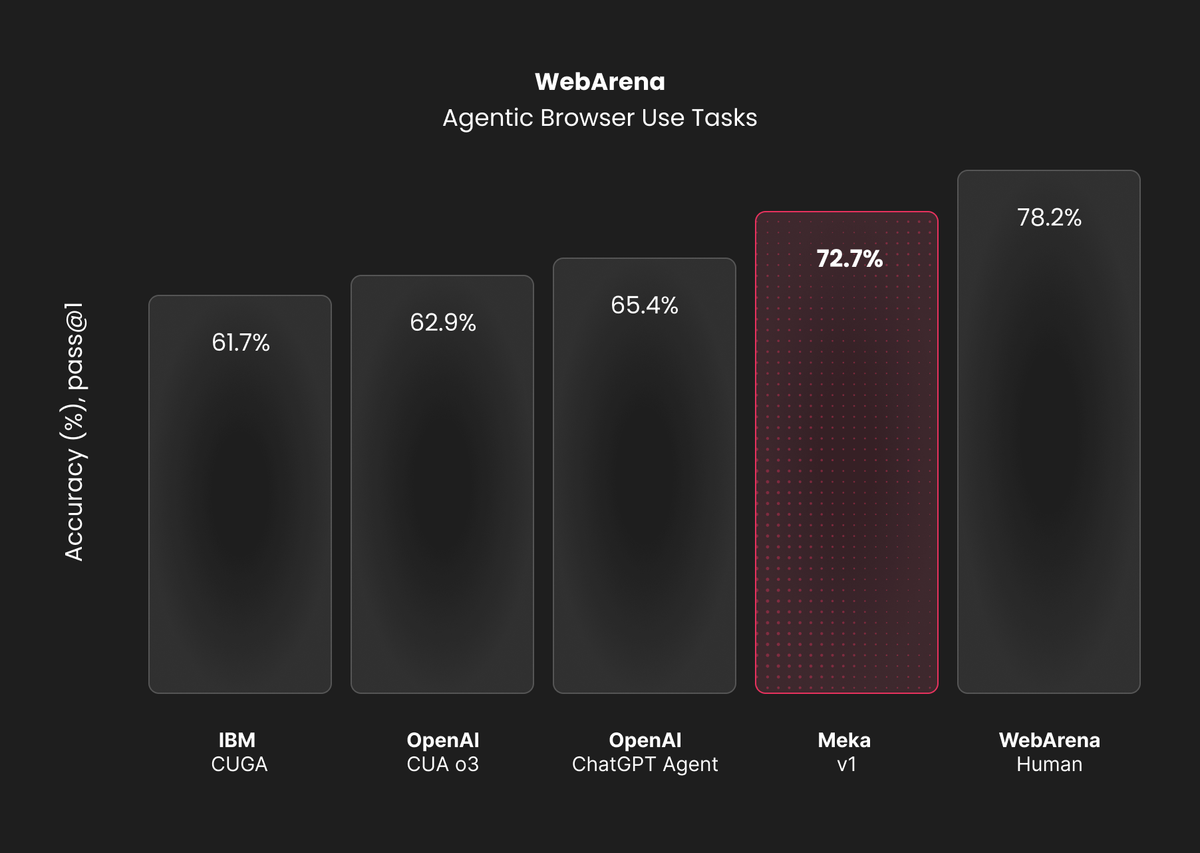
Meka establishes a new state-of-the-art in browser use benchmarks. Our computer agent achieved a 72.7% success rate across 651 diverse web tasks on WebArena, reflecting tasks involving shopping, store administration, Wikipedia, Reddit, and GitLab.
This post outlines detailed information on the WebArena evaluation, including results, environment, prompting, test execution and the scoring methodology used. To experience the agent yourself, you can use our cloud version here!
Benchmark Selection
We chose WebArena as our gold standard benchmark because we believe it has the most diverse and difficult set of tasks. In addition, the test environments are instantiated from Docker images which means they do not suffer from changes in live websites, and most accurately reflect consistent improvement in agent capabilities.
Evaluation Setup
The full dataset for the evaluation can be found here.
Test Modifications
We took the existing WebArena test suite and made several modifications to ensure its accuracy and robustness:
- Minor configuration changes: Correcting typos and URL mismatches in the shopping_admin tasks
- Exclusions of 161 "impossible" tasks:
- Map-related tests: The map tiling URL in the provided Docker container was broken, making these tasks impossible to complete. 128 tasks were excluded this way and marked as impossible to conduct due to environment configuration.
- Incorrect answers: The expected answers for some tasks were incorrect and hence impossible to answer. 33 tasks were excluded in this way. We made a manual determination if it's pass/fail and labelled them as EXCLUDE PASS/FAIL, but these were not included in the final results.
- Errors: Tasks that failed due to provider errors were rerun once. If they persisted as errors, they would be counted as failures. We encountered the following provider errors:
- browserType.connectOverCDP: Timeout 30000ms exceeded.
- Invalid prompt: your prompt was flagged as potentially violating our usage policy.
- Overload (API rate limits)
These modifications resulted in a total of 651 tasks for evaluation.
Test Environment
We ran the evaluations in a VM-based browser. The agent interacts with the browser through computer vision and simulated mouse/keyboard interactions.
The actual environment in which the test is run is as suggested by the WebArena team. The setup instructions for the test environments can be found on their GitHub repository.
Prompting
At the beginning of every prompt, we appended a mapping between the websites mentioned in the prompt and the URLs of their corresponding dummy environments (e.g., 'Reddit', we refer to the site ${SITE_URL.reddit}).
You are to stay within these domains and do not navigate to other domains. Make sure to wait for the page to properly load when navigating between pages.`
Test Execution
All results were obtained using pass@1. The benchmarks were run in cohorts of ~100 to minimize for provider errors.
We set a maximum of 125 steps and a total time limit of 60 minutes per task. Any tasks that exceed these steps or time limit are considered failures. A single step consists of a call to a model, and execution of any tool calls that were returned.
Scoring Methodology
We used a hybrid evaluation system that involved both manual review and automated evaluations via the harness provided by WebArena. A task is considered a "PASS" only if it passes all checks:
- program_html: This follows a port of what WebArena has ported from Python to TypeScript.
- LLM Check: For others, we use an LLM to judge the result. The judge gets the task, the agent's answer, and the expected outcome. It returns a "PASS" or "FAIL" along with its reasoning.
- Manual Review: We reviewed a sample of the FAIL and PASS results to double check for errors. Corrections from FAIL to PASS were made only for "flaky tests" where the evaluator selector was overly strict despite the correct answer. For example, expected: "January 20th, 2024" vs. actual "01/20/2024" would be changed from "FAIL" to "PASS".
Conclusion
Our Meka agent achieved a 72.7% success rate on the WebArena benchmark, representing a significant improvement of 7.3 percentage points over the previous state-of-the-art (65.4%). This performance approaches human-level capability (78.2%) while maintaining consistency across diverse web-based tasks.
The evaluation demonstrates robust performance across multiple domains:
- Shopping platforms with complex product catalogs and transaction flows
- Administrative interfaces requiring precise form filling and navigation
- Knowledge retrieval tasks on Wikipedia
- Social media interactions on Reddit
- Code collaboration workflows on GitLab
Try the cloud version today and give our GitHub a star.
Acknowledgments
We thank the WebArena team for providing the benchmark infrastructure and evaluation framework that enabled this comprehensive assessment.